The following was submitted to the NHSRdatasets package in 2020 but was too big as data to be accepted by the package (CRAN has size limits). However, the vignette that accompanied the data may be of interest and so is copied here as a blog. The data is also pulled from the GitHub Pull Request.
CQC Directory
This vignette explains how to use the cqc_load dataset in R, and also details where it comes from and how it is generated.
The data contains care provider locations and ratings as published monthly in 2019.
The dataset contains data on locations and providers:
location: location ID, name, ODS code, telephone number, web address, sector, inspection directorate, region, local authority, CCG, street address, parliamentary constituency, and coordinates.
provider: provider ID, name, company/charity registration, telephone number, web address, sector, inspection directorate, region, local authority, street address, and parliamentary constituency. code for the organisation that this activity relates to
pub_date: The date that particular data point was published
First let’s load some packages and the dataset and show the first 10 rows of data.
NoteData location
The following code has had all references to the NHSRdatasets package removed as the data wasn’t added to it.
library(dplyr)library(knitr)library(tidyr)library(ggplot2)library(lubridate)library(magrittr)# Although the data isn't in NHSRdatasets it can be downloaded from the Pull Request using this codeload(url("https://github.com/MHWauben/NHSRdatasets/raw/274688bc727e800d5c40f06f86be38f866167818/data/cqc_directory.rda"))# format for displaycqc_load%>%# show the first 10 rowshead(10)%>%# format as a tablekable()
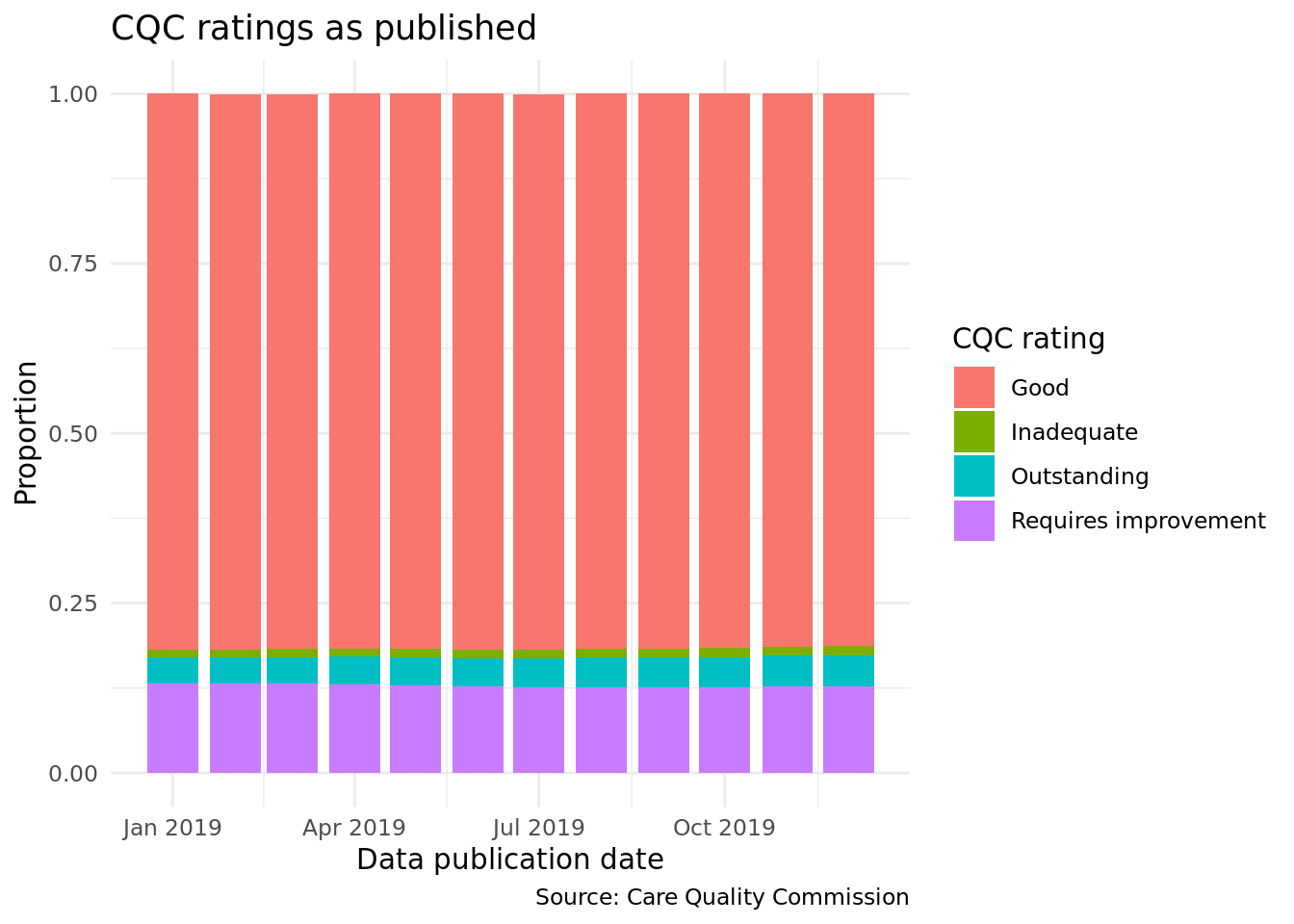
We can now plot, for each month, the proportion of locations that received each rating:
ggplot(rat_overtime, aes(pub_date, number, fill =location_latest_overall_rating))+geom_bar(stat ="identity", position ="fill")+theme_minimal()+labs( x ="Data publication date", y ="Proportion", fill ="CQC rating", title ="CQC ratings as published", caption ="Source: Care Quality Commission")
Although the raw numbers show increases in each rating, this is primarily driven by more and more locations becoming available: proportionally, performance has remained fairly stable at a national level.
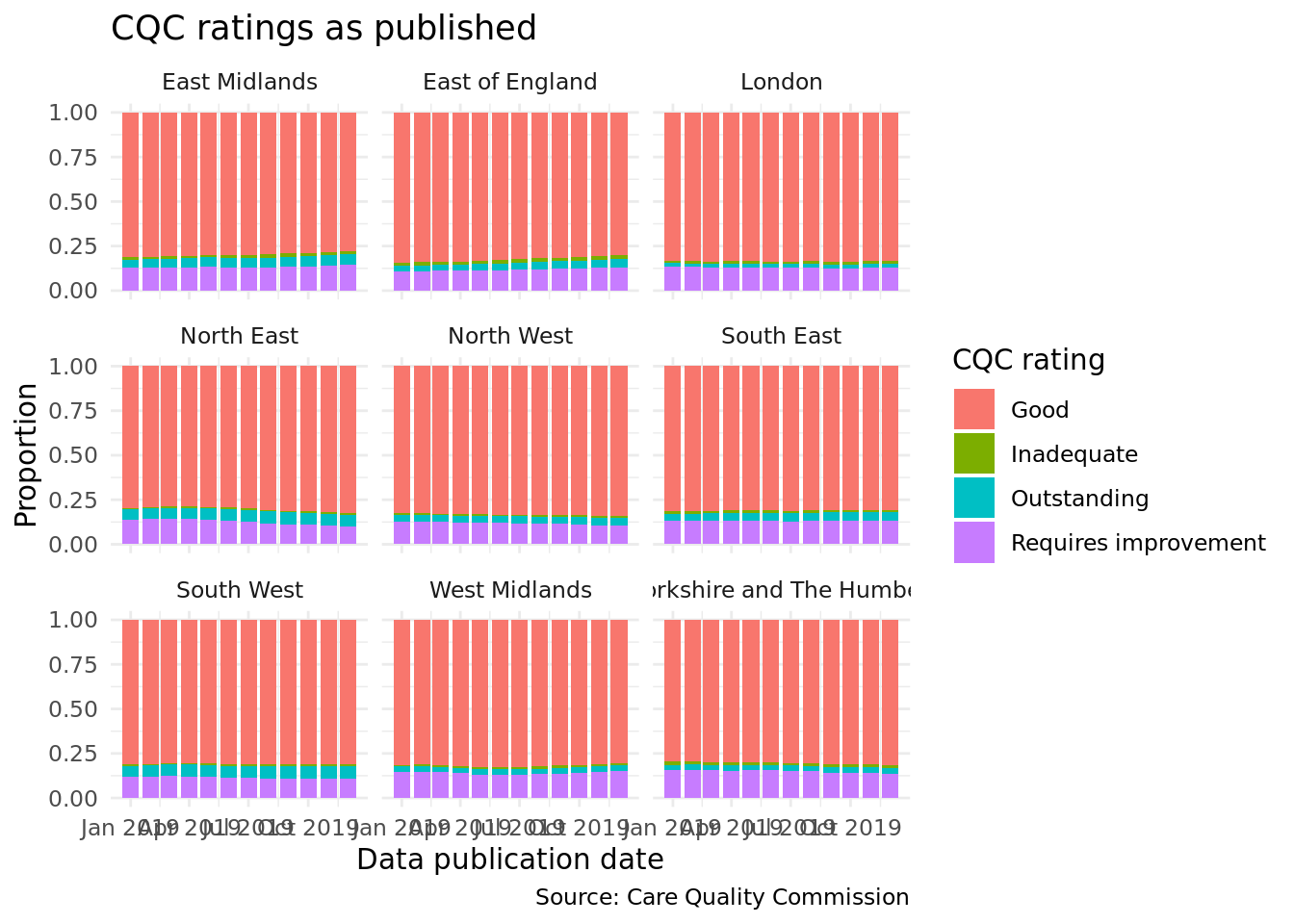
We can further break this down by region to better understand what is happening:
region_ratings_overtime<-cqc_load%>%group_by(pub_date, location_region, location_latest_overall_rating)%>%summarise(number =dplyr::n())%>%filter(!is.na(location_latest_overall_rating)&!(location_region%in%c("Unspecified", "(pseudo) Wales")))%>%ungroup()%>%mutate(pub_date =as.Date(pub_date))ggplot(region_ratings_overtime, aes(pub_date, number, fill =location_latest_overall_rating))+geom_bar(stat ="identity", position ="fill")+theme_minimal()+facet_wrap(~location_region)+labs( x ="Data publication date", y ="Proportion", fill ="CQC rating", title ="CQC ratings as published", caption ="Source: Care Quality Commission")
More interesting patterns emerge now: some regions have growing proportions of ‘Good’ or ‘Outstanding’ locations, whereas others are seeing increases in locations requiring improvement.
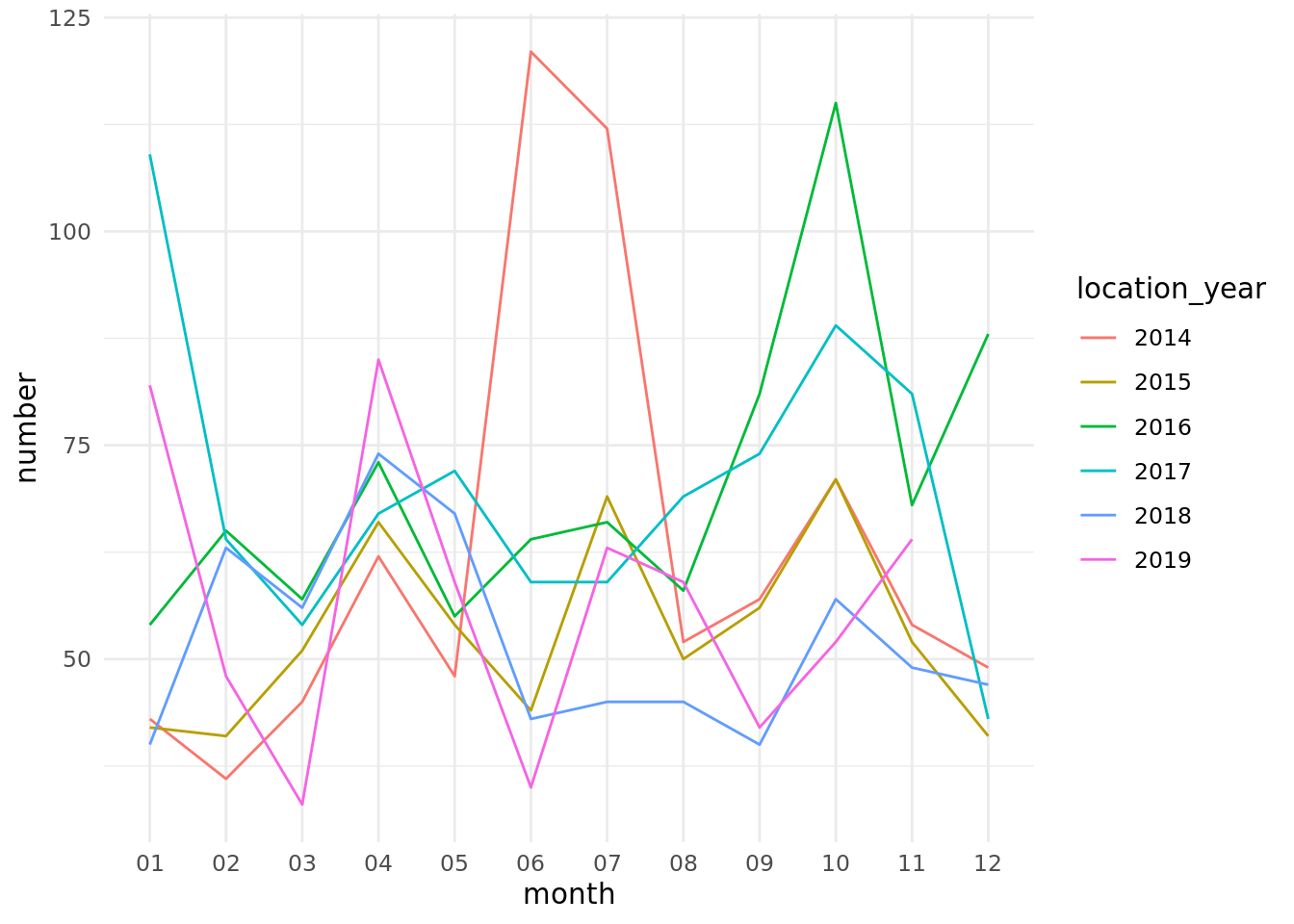
How many new care homes are being opened?
With an ageing population, there is increasing demand for care home beds. Is supply keeping up?
carehome_openings<-cqc_load%>%mutate(location_hsca_start_date =as.Date(location_hsca_start_date))%>%filter(care_home=="Y"&location_hsca_start_date>="2014-01-01"&!(location_region%in%c("Unspecified", "(pseudo) Wales"))&pub_date==max(as.Date(pub_date)))%>%mutate(location_month =floor_date(location_hsca_start_date, unit ="month"))%>%group_by(location_month)%>%summarise( number =n(), beds =sum(as.integer(care_homes_beds)))%>%mutate( location_year =as.factor(format(floor_date(location_month, unit ="year"), "%Y")), month =format(location_month, "%m"))ggplot(carehome_openings, aes(x =month, y =number, colour =location_year, group =location_year))+geom_line()+theme_minimal()
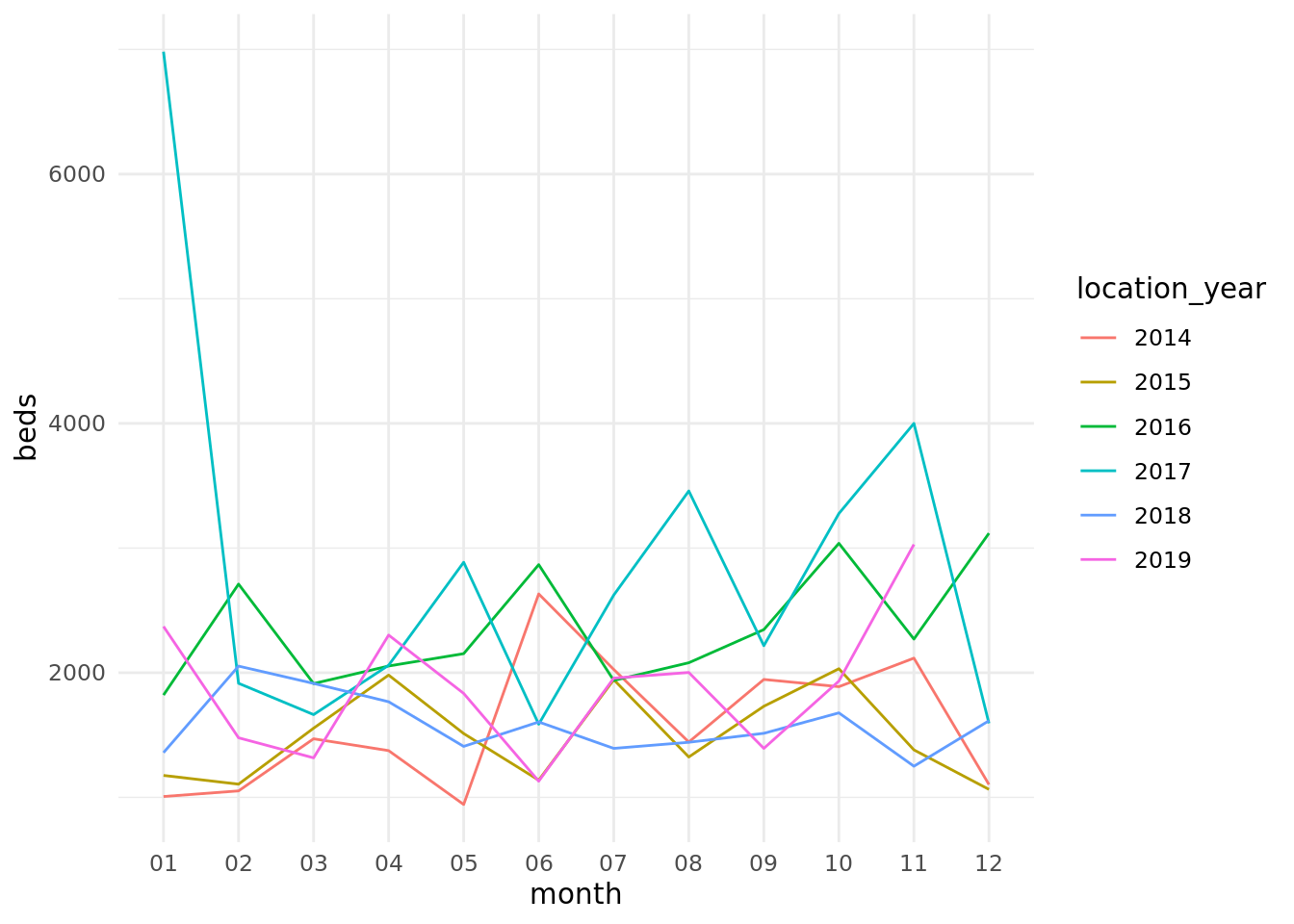
It is likely that the 2019 timeseries drops off due to a delay between provision starting and CQC reporting data. However, overall the number of new care homes opening is not increasing! Perhaps each care home is getting bigger; how many new beds are becoming available?
ggplot(carehome_openings, aes(x =month, y =beds, colour =location_year, group =location_year))+geom_line()+theme_minimal()
This is a bit more encouraging: in 2016 and 2017, there was a good uptick in new care home beds. However, 2018 did not perform quite as well. Still, 2019 appears to be going in the right direction!