Inspired by conversations on the NHS-R Slack where code answers are lost over time (it’s not a paid account), and also for those times when a detailed comment in code isn’t appropriate but would be really useful, this blog is part of a series of code snippet explanations.
Where this code snippet comes from
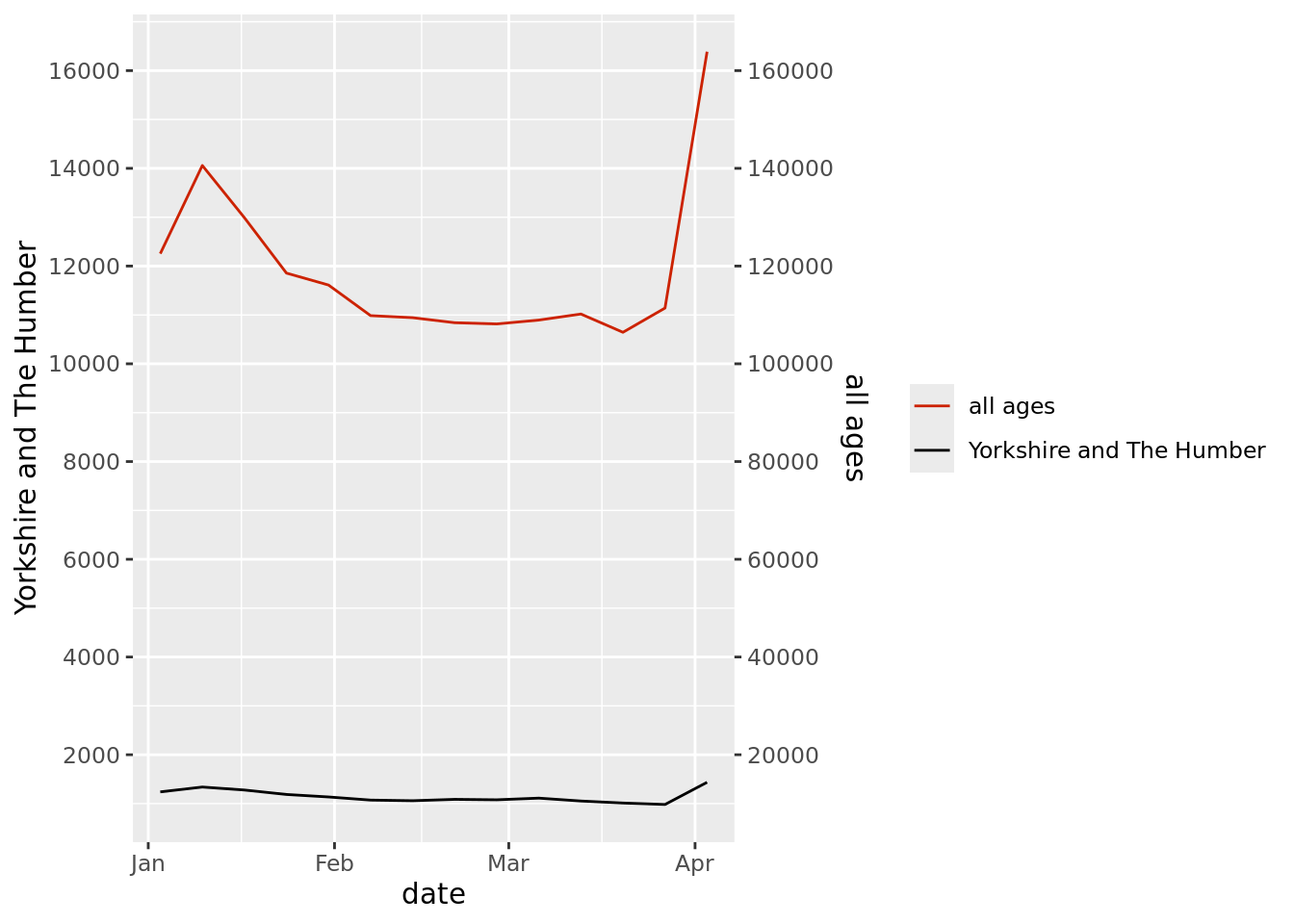
A question was posed on the NHS-R Slack asking for help to code 2 scale y axes on a {ggplot2} chart. Responses included code but the post sparked a conversation around why this can be misleading.
From experience, I wrote how I’d shown a chart over many years of the regional mortality with the left axis and the Trust mortality numbers on the right axis created using {digraphs} and to show the similar pattern in seasonal deaths that affected the Trust deaths as a smaller part of the larger East Midlands region. Although the chart had been shown many times to a group and the fact that although the line for the left (higher 1,000s regional) crossed above the right (lower 100s Trust) the axis represented very different totals. It was by a chance encounter with someone from the meeting that it became clear that this chart had not really been understood and the assumption – which is reasonable given the majority of charts do this – was that the Trust deaths became higher than the East Midlands region over time as the lines had crossed.
There are many examples of why not to do use dual axes by other blogs such as:
but as people have noted in Journal articles and on Stackoverflow sometimes they have a use and also if we are asked for a two scale y axes, saying that it’s not appropriate doesn’t stop the request.
When I’ve had issues where I’ve not agreed with the chart request I’ve presented the alternative and, having done the work beforehand rather than explaining the theory, I’ve managed to get the outcome I wanted which was not to use that chart.
In terms of {ggplot2} the alternatives are using the facet() function, perhaps with the addition of facet(~ column, ncol = 1) to switch the facets from being side to side to being in a column. The change in view can give different insight and meaning and it’s always worth seeing the same thing in different ways. But always remember too that, as analysts and data scientists, that we work with data and charts all day and so some things are more obvious to us and never assume what you see is what others see.
Code answer
This was adapted from the answer on the NHS-R Slack and uses the {NHSRdatasets} package which is available through CRAN
library(dplyr, warn.conflicts =FALSE)library(tidyr)library(ggplot2)library(NHSRdatasets)library(janitor, warn.conflicts =FALSE)# to clean the titles and making them snake_caseons_mortality<-NHSRdatasets::ons_mortalitydeaths_data<-ons_mortality|>filter(date>"2020-01-01",category_2%in%c("all ages", "Yorkshire and The Humber"))|>pivot_wider( id_cols =c(date, week_no), values_from =counts, names_from =category_2)|>clean_names()ggplot(data =deaths_data)+geom_line(aes( x =date, y =all_ages, col ="all ages"))+geom_line(aes( x =date, y =yorkshire_and_the_humber, col ="Yorkshire and The Humber"))+scale_y_continuous( name ="Yorkshire and The Humber", breaks =scales::pretty_breaks(10), sec.axis =sec_axis(~.*10, name ="all ages", breaks =scales::pretty_breaks(10)))+scale_colour_manual( name =NULL, values =c("all ages"="#CC2200","Yorkshire and The Humber"="black"))
Getting involved
If you need any help with {dplyr} or would like to share your own use cases feel free to share them in the NHS-R Slack or submit a blog for this series.
NHS-R Community also have a repository for demos and how tos which people are welcome to contribute code to either through pull requests or issues.