Can we rely on synthetic data to overcome data governance issue in healthcare?
Synthetic dataset
Data
base R
Authors
Muhammad Faisal
Gary Hutson
Published
April 22, 2021
Modified
July 12, 2024
I recently came across a term synthetic data. I start wondering what does it mean? I found that it is different from the dummy data, but in what ways and how is it different, I began to wonder?
I become curious to find out more about it, as nowadays it is difficult to get hold of healthcare data (that is., NHS). The most prominent issues seem to link to data governance and access, as this information is personal sensitive data.
I investigated methods for creating ‘synthetic data’ as a tool that might help to develop better prediction models, as data could be available for a much larger pool of people, who can tackle these data governance and other challenging healthcare issues.
What is Synthetic data?
The goal is to generate a data set which contains no real units, therefore safe for public release and retains the structure of the data.
In other words, one can say that synthetic data contains all the characteristics of original data minus the sensitive content.
Synthetic data is generally made to validate mathematical models. This data is used to compare the behaviour of the real data against the one generated by the model.
How we generate synthetic data?
The principle is to observe real-world statistic distributions from the original data and reproduce fake data by drawing simple numbers.
Consider a data set with p variables. In a nutshell, synthesis follows these steps:
Take a simple random sample of x1,obs and set as x1,syn
Fit model f(x2,obs|x1,obs) and draw x2,syn from f(x2,syn|x1,syn)
Fit model f(x3,obs|x1,obs , x2,obs ) and draw x3,syn from f(x3,syn|x1,syn , x2,syn )
And so on, until f(xp,syn|x1,syn , x2,syn , … , xp-1,syn)
Fitting statistical models to the original data and generating completely new records for public release.
Joint distribution f(x1, x2, x3, …, xp) is approximated by a set of conditional distributions f(x2|x1).
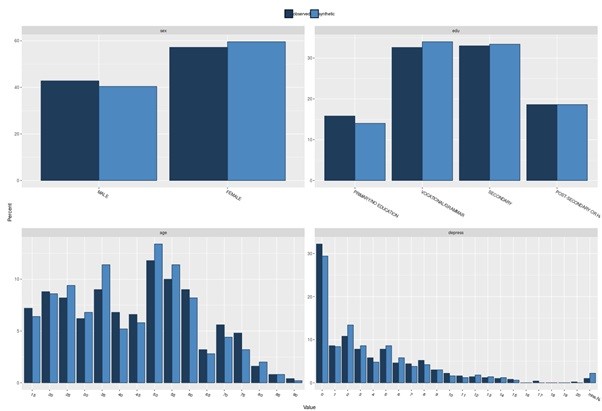
For instance, we have the following original (real) data.
male age NEWS syst
Min. :0.000 Min. : 17.00 Min. : 0.000 Min. : 65.0
1st Qu.:0.000 1st Qu.: 60.00 1st Qu.: 1.000 1st Qu.:118.0
Median :0.000 Median : 74.00 Median : 2.000 Median :134.0
Mean :0.476 Mean : 69.65 Mean : 2.444 Mean :135.7
3rd Qu.:1.000 3rd Qu.: 84.00 3rd Qu.: 4.000 3rd Qu.:150.0
Max. :1.000 Max. :102.00 Max. :12.000 Max. :220.0
dias temp pulse resp
Min. : 17.00 Min. :33.10 Min. : 40.0 Min. :10.00
1st Qu.: 63.00 1st Qu.:35.80 1st Qu.: 70.0 1st Qu.:16.00
Median : 74.00 Median :36.20 Median : 84.0 Median :18.00
Mean : 74.63 Mean :36.31 Mean : 85.8 Mean :18.39
3rd Qu.: 84.00 3rd Qu.:36.70 3rd Qu.: 98.0 3rd Qu.:20.00
Max. :124.00 Max. :40.20 Max. :200.0 Max. :43.00
sat sup alert died
Min. : 82.00 Min. :0.000 Min. :0.000 Min. :0.00
1st Qu.: 95.00 1st Qu.:0.000 1st Qu.:0.000 1st Qu.:0.00
Median : 97.00 Median :0.000 Median :0.000 Median :0.00
Mean : 96.38 Mean :0.123 Mean :0.071 Mean :0.07
3rd Qu.: 98.00 3rd Qu.:0.000 3rd Qu.:0.000 3rd Qu.:0.00
Max. :100.00 Max. :1.000 Max. :3.000 Max. :1.00
Generate the synthetic NEWS data using synthpop R package
Warning: In your synthesis there are numeric variables with 5 or fewer levels: male, sup, alert, died.
Consider changing them to factors. You can do it using parameter 'minnumlevels'.
Synthesis
-----------
male age NEWS syst dias temp pulse resp sat sup
alert died
male age NEWS syst
Min. :0.00 Min. : 17.00 Min. : 0.000 Min. : 65.0
1st Qu.:0.00 1st Qu.: 60.00 1st Qu.: 1.000 1st Qu.:118.0
Median :0.00 Median : 74.00 Median : 1.000 Median :135.0
Mean :0.47 Mean : 69.99 Mean : 2.414 Mean :136.2
3rd Qu.:1.00 3rd Qu.: 84.00 3rd Qu.: 4.000 3rd Qu.:150.2
Max. :1.00 Max. :102.00 Max. :11.000 Max. :219.0
dias temp pulse resp
Min. : 17.0 Min. :33.10 Min. : 43.00 Min. :12.00
1st Qu.: 63.0 1st Qu.:35.80 1st Qu.: 70.00 1st Qu.:16.00
Median : 74.0 Median :36.20 Median : 83.00 Median :18.00
Mean : 74.6 Mean :36.26 Mean : 85.04 Mean :18.57
3rd Qu.: 84.0 3rd Qu.:36.70 3rd Qu.: 97.00 3rd Qu.:20.00
Max. :124.0 Max. :40.20 Max. :200.00 Max. :43.00
sat sup alert died
Min. : 82.00 Min. :0.000 Min. :0.000 Min. :0.000
1st Qu.: 95.00 1st Qu.:0.000 1st Qu.:0.000 1st Qu.:0.000
Median : 97.00 Median :0.000 Median :0.000 Median :0.000
Mean : 96.45 Mean :0.125 Mean :0.059 Mean :0.062
3rd Qu.: 98.00 3rd Qu.:0.000 3rd Qu.:0.000 3rd Qu.:0.000
Max. :100.00 Max. :1.000 Max. :3.000 Max. :1.000
In many ways, synthetic data reflects George Box’s observation that “all models are wrong, but some are useful” while providing a “useful approximation [of] those found in the real world,”
The connection between the clinical outcomes of a patient visits and costs rarely exist in practice, so being able to assess these trade-offs in synthetic data allow for measurement and enhancement of the value of care – cost divided by outcomes.
Synthetic data is likely not a 100% accurate depiction of real-world outcomes, like cost and clinical quality, but rather a useful approximation of these variables. Moreover, synthetic data is constantly improving, and methods like validation and calibration will continue to make these data sources more realistic.
Besides synthetic data used to protect the privacy and confidentiality of set of data, it can be used for testing fraud detection systems by creating realistic behaviour profiles for users and attackers. In machine learning, it can also be used to train and test models. The synthetic data can aid in creating a baseline for future testing or studies such as clinical trial studies.